
1. Background
As enterprise businesses increasingly demand higher database availability, MySQL InnoDB Cluster (hereinafter referred to as MIC), as MySQL's official high-availability solution, has been widely adopted in production environments. This solution, based on MySQL Group Replication and the MySQL Shell management tool, provides key features such as automatic failure detection and recovery, and data consistency guarantees.
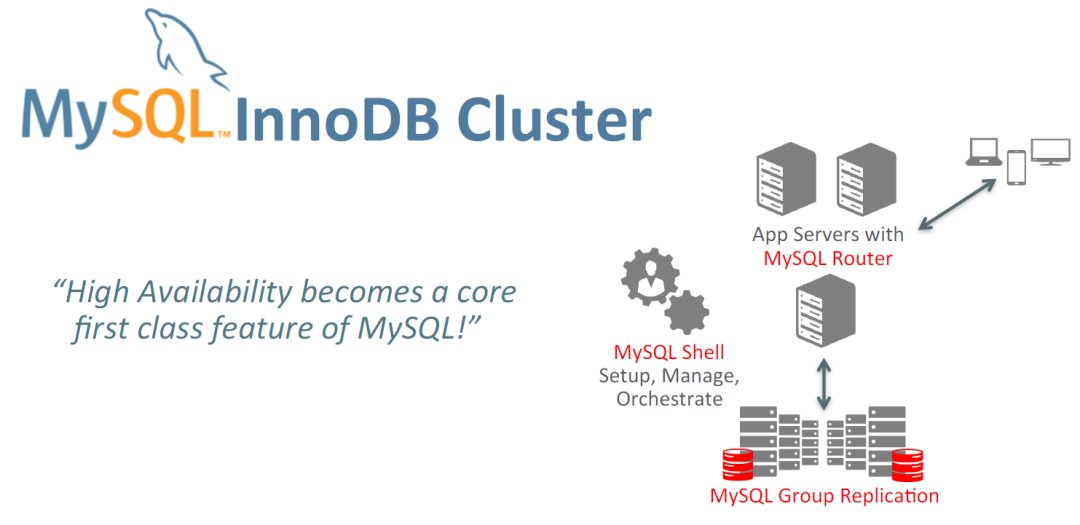
However, during actual operations, clusters may still face various abnormal situations due to factors like hardware failures, network issues, and configuration errors. To ensure the continuous and stable operation of database services, MySQL administrators need the ability to quickly diagnose and recover cluster failures.
This article, based on experience from actual production environments, tests common MIC failure scenarios and provides corresponding recovery plans and operational guidance. It aims to help MySQL administrators improve failure handling efficiency and ensure business continuity.
Test Environment Information
OS: Red Hat Enterprise Linux release 8.10 (Ootpa)
MySQL: mysql-community-server-8.4.5-1.el8.x86_64
mysqlshell: mysql-shell-8.4.5-1.el8.x86_64
mysqlrouter: mysql-router-community-8.4.5-1.el8.x86_64
2. Scenario Examples
Scenario 1: Restarting a Non-Primary Cluster Node
Failure Simulation: Restart the node2Secondary node
-- node2
systemctl restart mysql
-- node1
mysqlsh --uri clusteruser@10.186.65.13:3306
\js
var cluster=dba.getCluster()
cluster.status()
Recovery Process
-- Log in to mysqlshell to check the initial cluster status
[root@node1 ~]# mysqlsh --uri clusteruser@10.186.65.13:3306
MySQL Shell 8.4.5
...
MySQL 10.186.65.13:3306 ssl JS > var cluster=dba.getCluster()
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
All members in the cluster have a status of "ONLINE", node1 is the "PRIMARY" node, node2/3 are "SECONDARY" nodes.
-- Observe cluster status during the node2 instance restart
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK_NO_TOLERANCE_PARTIAL",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013: Could not open connection to 'node2:3306': Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
Connection to node2 via mysqlshell reports Error 2013, the node status becomes "(MISSING)".
-- Check cluster status again after the node2 instance restart completes
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
After the instance on node2 automatically restarts, the cluster recovers automatically without additional steps.
Summary
- Failure Phenomenon:
node2status shows as(MISSING)during restart.- Cluster status changes to
OK_NO_TOLERANCE_PARTIAL. - Connection error
Lost connection to MySQL serverappears.
- Recovery Key Points:
- After the Secondary node restarts, the cluster can automatically detect and rejoin it.
- No manual intervention required; automatically recovers to
ONLINEstatus. - The cluster can still serve normally during the single-node failure.
- Impact Scope:
- Fault tolerance drops to 0 during the restart.
- No impact on application read/write operations.
- Brief impact on read load balancing.
Scenario 2: Secondary Node Instance Failure
Failure Simulation: Stop and then start the node3Secondary node
-- node3:
systemctl stop mysql
-- node1:
mysqlsh --uri clusteruser@10.186.65.13:3306
var cluster=dba.getCluster()
cluster.status()
-- node3:
systemctl start mysql
Recovery Process
-- Initial cluster status
Same as above, omitted...
-- Check cluster status after stopping the instance on node3
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK_NO_TOLERANCE_PARTIAL",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013: Could not open connection to 'node3:3306': Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
mysqlshell connection to the instance on node3 reports an error, node status is "(MISSING)".
-- Check cluster status again after restarting the node3 instance
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
After starting the failed instance on node3, the cluster recovers automatically without additional steps.
Summary
- Failure Phenomenon:
node3status shows as(MISSING).- Cluster status is
OK_NO_TOLERANCE_PARTIAL. - Connection error
Lost connection to MySQL serverappears.
- Recovery Key Points:
- The stopped Secondary node automatically recovers after restarting.
- The cluster automatically resynchronizes data.
- The entire process requires no manual intervention.
- Impact Scope:
- The cluster loses fault tolerance during the failure.
- Read load capacity decreases.
- Writes to the Primary node are unaffected.
Scenario 3: Network Split Between Primary and Secondary Nodes
Failure Simulation: Disconnect the network between node1(Primary) and the other Secondary nodes.
-- node1:
./stop_net.sh
cat stop_net.sh
#!/bin/bash
iptables -A INPUT -s 10.186.65.18 -j DROP
iptables -A OUTPUT -d 10.186.65.18 -j DROP
iptables -A INPUT -s 10.186.65.24 -j DROP
iptables -A OUTPUT -d 10.186.65.24 -j DROP
sleep 30
iptables -F
-- node1:
mysqlsh --uri clusteruser@10.186.65.13:3306
\js
var cluster=dba.getCluster()
cluster.status()
Recovery Process
-- Initial cluster status
Same as above, omitted...
-- Cluster status during network disconnection script execution
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "NO_QUORUM",
"statusText": "Cluster has no quorum as visible from 'node1:3306' and cannot process write transactions. 2 members are not active.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"memberState": "(MISSING)",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2003: Could not open connection to 'node2:3306': Can't connect to MySQL server on 'node2:3306' (110)",
"status": "UNREACHABLE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"memberState": "(MISSING)",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2003: Could not open connection to 'node3:3306': Can't connect to MySQL server on 'node3:3306' (110)",
"status": "UNREACHABLE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
Currently, memberState for node2/3 is "(MISSING)", mysqlshell cannot connect, node status is "UNREACHABLE".
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "NO_QUORUM",
"statusText": "Cluster has no quorum as visible from 'node1:3306' and cannot process write transactions. 2 members are not active.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"memberState": "(MISSING)",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2003: Could not open connection to 'node2:3306': Can't connect to MySQL server on 'node2:3306' (110)",
"status": "UNREACHABLE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"instanceErrors": [
"ERROR: split-brain! Instance is not part of the majority group, but has state ONLINE"
],
"memberRole": "SECONDARY",
"memberState": "ONLINE",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"status": "UNREACHABLE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
Now, the cluster status is slightly different: node2's memberState and status remain unchanged, while node3's memberState becomes "ONLINE", showing a split-brain warning.
-- Simultaneously check the cluster status on node2
MySQL 10.186.65.18:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"instanceErrors": [
"WARNING: Instance is NOT a PRIMARY but super_read_only option is OFF."
],
"memberRole": "SECONDARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
Currently, the network between node2/3 is normal; only the network between node1 and them is split. The majority of the cluster (node2, node3) is still normal and no Primary switchover has occurred.
-- After network recovery, check the cluster status again on node1
MySQL 10.186.65.13:3306 ssl JS > cluster.status()
{
"clusterName": "mycluster",
"defaultReplicaSet": {
"name": "default",
"primary": "node1:3306",
"ssl": "DISABLED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"node1:3306": {
"address": "node1:3306",
"memberRole": "PRIMARY",
"mode": "R/W",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node2:3306": {
"address": "node2:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
},
"node3:3306": {
"address": "node3:3306",
"memberRole": "SECONDARY",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "applier_queue_applied",
"role": "HA",
"status": "ONLINE",
"version": "8.4.5"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "node1:3306"
}
After network status recovers, the cluster status viewed on node1 also returns to normal.
Summary
- Failure Phenomenon:
- Primary node shows
NO_QUORUMstatus. - Secondary nodes show
UNREACHABLE. - Split-brain warning may appear:
split-brain! Instance is not part of the majority group.
- Primary node shows
- Recovery Key Points:
- After network recovery, the cluster automatically re-establishes connections.
- Automatic data consistency checks are performed.
- Primary and Secondary roles are automatically negotiated and determined.
- Impact Scope:
- Write operations may be blocked during the network partition.
- Ensuring majority consensus is required.
- Data conflicts may arise and need resolution.
Summary
- Failure Phenomenon:
- Automatic failover occurs during Primary node restart.
node2is elected as the new Primary node.- The original Primary node status is
(MISSING)after restart.
- Recovery Key Points:
- The cluster automatically
%20(2048%20x%201000%20%E5%83%8F%E7%B4%A0)%20(3).png)

%20(2048%20x%201000%20%E5%83%8F%E7%B4%A0)%20(2).png)
